Problem Statement
- USA based client with India captive center has proprietary OCR based AI platform where they receive large number of transactional documents from various clients from different sources, like invoices, insurance papers, etc. The document files are in pdf and tiff formats and many times they are in large numbers.
- Client defined this research project to have AI algorithms to convert all such ‘Devnagari’ script-based documents in single format and later extract all images in optimized way to be used for further processing in OCR platform.
Solution
-
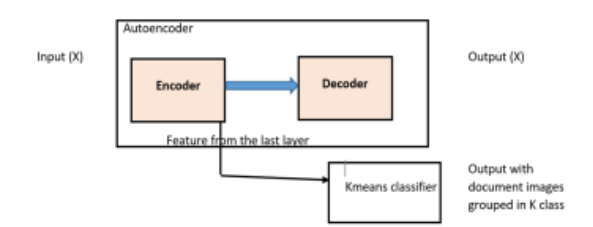
- An autoencoder is first trained using the pre-processed dataset with input and output as the images from the dataset
.
- The autoencoder is designed for training with convolutional and max-pooling layers in the decoder and convolutional and up-sampling layers in the decoder
- The last feature layer of the encoder from the trained autoencoder is stored in some tensor variable.
- The last feature layer of the encoder is then used for training the K- means classifier with K being chosen manually.
Salesforce Development for Leading K-12 School Chain in USA